18.05.2023 Экспертиза, Искусственный интеллект, Менеджмент
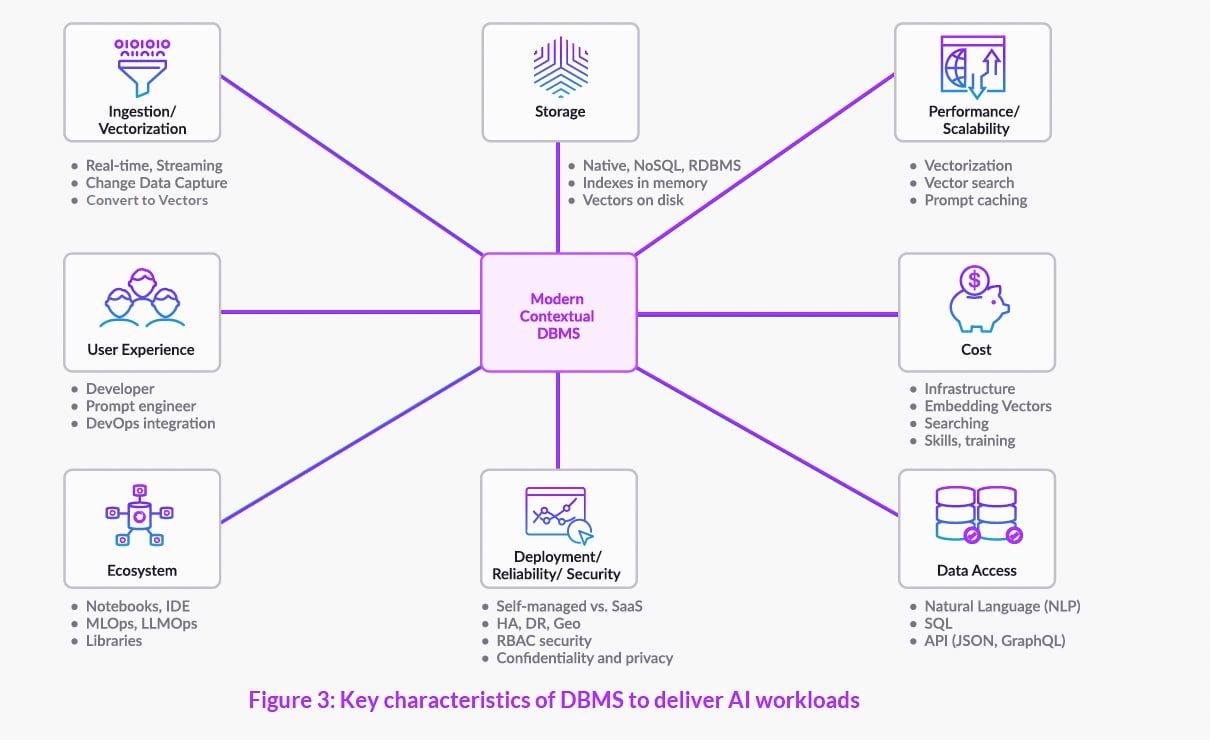
Санджив Мохан, директор компании SanjMo, и Мадхукар Кумар, директор по маркетингу компании SingleStore, обсуждают на портале The New Stack восемь компонентов, которые необходимо учитывать при оценке новой или существующей базы данных для обработки рабочих нагрузок генеративного искусственного интеллекта. Кажется, что почти каждый день появляется новое приложение ИИ, которое расширяет границы возможного. Несмотря на все внимание, которое привлекает к себе генеративный ИИ, некоторые его громкие ошибки еще раз напомнили миру о том, что «мусор на входе, мусор на выходе». Если мы игнорируем основополагающие принципы управления данными, то полученным результатам нельзя доверять. Чтобы использовать новые большие языковые модели (LLM) и открыть для себя новые возможности, техническим специалистам придется не только изменить свою стратегию работы с данными и существующую инфраструктуру данных, но и определить, какие технологии являются лучшими и наиболее эффективными для обеспечения рабочих нагрузок ИИ. Рассмотрим, какие компоненты баз данных необходимы организациям для использования возможностей LLM на собственных данных. Восемь компонентов для поддержки рабочих нагрузок ИИ Базы данных, поддерживающие рабочие нагрузки ИИ, должны обеспечивать низкую задержку и высокую масштабируемость запросов. Мир LLM расширяется очень быстро — некоторые модели полностью открыты, другие полуоткрыты, но имеют коммерческие API. При принятии решения о том, как оценить новую или существующую базу данных ...
читать далее.