09.06.2023 Экспертиза, Искусственный интеллект, Мобильные и беспроводные решения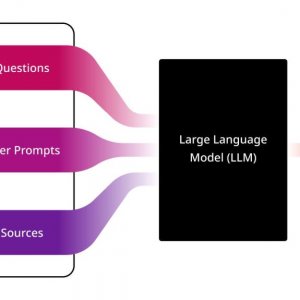
Простая схема того, как LLM собирает контекст для создания ответа
Создание приложений, предлагающих беспрецедентные уровни персонализации контекста, становится реальностью при наличии надлежащей базы данных, нескольких строк кода и большой языковой модели (LLM) типа GPT-4, пишет на портале The New Stack Эд Ануфф, директор по продуктам компании DataStax. Искусственный интеллект — это самая трансформационная смена парадигмы с момента появления Интернета в 1994 г. И это заставило многие корпорации, что вполне понятно, броситься внедрять ИИ в свой бизнес. Одним из наиболее важных способов является применение генеративного ИИ и LLM, и речь идет далеко не только о просьбе к ChatGPT написать пост на определенную тему для корпоративного блога или даже помочь написать код. На самом деле, LLM быстро становятся неотъемлемой частью стека приложений. Создание интерфейсов — «агентов» — генеративного ИИ, таких как ChatGPT, к содержащей все необходимые данные базе данных, способных «говорить на языке» LLM, — это будущее (и, все чаще, настоящее) мобильных приложений. Уровень динамического взаимодействия, доступ к огромным объемам открытых и закрытых данных и способность адаптироваться к конкретным ситуациям делают приложения, созданные на основе LLM, мощными и увлекательными в такой мере, которая была недоступна до недавнего времени. И эта технология быстро развилась до такой степени, что создавать такие приложения может практически любой человек, имеющий надлежащие базу данных и подходящие API. Давайте посмотрим, что для этого нужно. Генеративный ...
читать далее.








